I have been spending a lot of time on one-step generative models, specifically MeanFlow and the broader family it belongs to. This is my attempt to build an honest mental model of how these methods work, where the math comes from, and how each one is a response to the limitations of the one before it.
The context: diffusion and flow models can now produce images, audio, and video that are nearly indistinguishable from real data, but generating a single sample requires hundreds of sequential network evaluations. A 1024×1024 image from a model like SDXL at 50 steps takes several seconds on an A100; a one-step distilled model produces the same resolution in tens of milliseconds. That is fine for offline synthesis. It is nearly unusable for anything interactive or real-time. The last two years, people have been trying hard to fix this, and the results are surprisingly good.
Starting from the goal and working backwards: what does a network need to learn to generate in one step?
Generation as transport
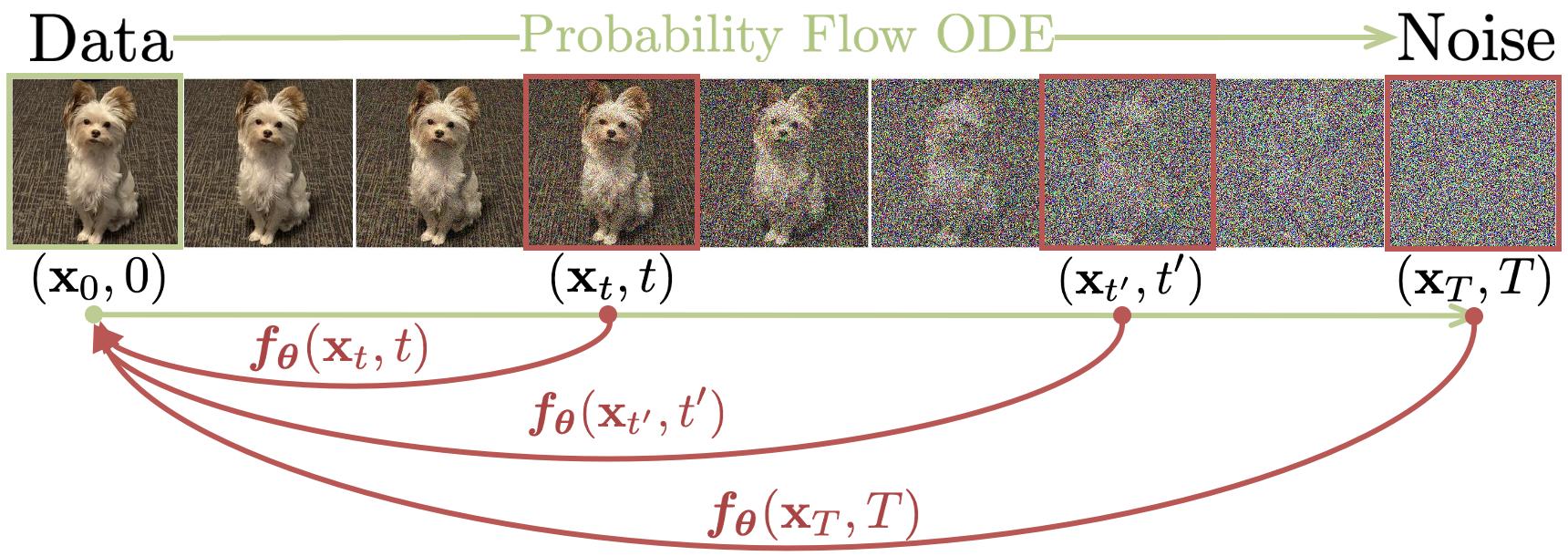
Generating a sample (say, an image of a dog) is moving probability mass from a noise distribution to the data distribution. In general this transport can be either stochastic (a forward and reverse diffusion SDE) or deterministic (an ODE); every method in this post lives in the deterministic regime, on a path called the probability flow ODE (PF-ODE) [11].1 Parameterise it by time $t$ running from $t=1$ (pure Gaussian noise) to $t=0$ (a clean data sample, like our dog). Write $z_t$ for the point on the trajectory at time $t$, and $x_0$ for the clean data sample at $t=0$. Because it is deterministic, you can run it forwards or backwards exactly.
Think of a soap bubble. Press it slowly and the surface deforms; every point on the film follows a smooth path. Release the pressure and it snaps back along the exact same path, not an approximation. The PF-ODE is that elastic surface in probability space, and $z_t$ is one spot on the surface at time $t$.
Standard diffusion and flow models learn to estimate the PF-ODE velocity locally, then numerically solve the learned ODE step by step from noise to data. At each $z_t$ the network tells you how fast and in which direction to move to keep heading toward the dog (or whatever target the trajectory points to). Apply that, take a step, repeat.
The core problem with step-by-step integration: the local velocity at $z_t$ tells you nothing about where the trajectory ends up globally. You have to follow it closely, one small step at a time, or you drift off course and end up somewhere wrong. This is expensive.
Two strategies:
- Jump to the endpoint directly. Learn a function that maps any trajectory point to $x_0$ in one shot. This is the consistency model [2] idea.
- Jump to any point, not just the endpoint. Learn a two-time function that can jump from any $t$ to any $s < t$ in one step. This is the flow map idea, and it is what consistency trajectory models (CTM), shortcut models, and MeanFlow build on.
Flow matching
Flow matching is the foundation every one-step method either builds on or borrows training structure from, so the rest of the post assumes the setup. Flow matching [1] frames generation as transport: learn a continuous-time flow that moves probability mass from one distribution to another. The source and destination can be any two distributions; unlike diffusion, which fixes the noisy end to Gaussian noise by construction, flow matching has no such constraint. In practice, the simplest useful case uses Gaussian noise as the source, giving straight-line paths between noise and data:2
The velocity at any point on this path is constant: $v = x_0 - x_1$. It is directly computable from a training pair $(x_0, x_1)$, no integration or simulation needed. A neural network $v_\theta(z_t, t)$ is then trained to predict this velocity at every $(z_t, t)$, by minimising the regression loss $\lVert v_\theta(z_t, t) - (x_0 - x_1) \rVert^2$. Clean supervised learning against a ground-truth target.
Inference is still slow, though. Even though each individual path $x_0 \leftrightarrow x_1$ is a straight line, the marginal velocity field is not. At any given noisy image $z_t$, many different clean images $x_0$ are plausible, not just one. Each candidate has its own straight-line velocity pointing in a slightly different direction. The network has to output the probability-weighted average of all those directions, which traces a curved path through image space. Following a curved path with only local velocity information requires many small steps.
Scrub the demo below to watch this happen: at $t=1$ the field points toward the centroid (no cluster has been chosen), and as $t$ decreases the weights concentrate and particles fan out toward different clusters. Try the candidates buttons (1, 3, 5) to see how a single cluster gives a uniform field while multiple clusters force curvature.
1 destination: field is uniform everywhere. A single step from any noise point lands exactly at x₀.
Flow matching gives you a simple regression objective at training time but slow inference. The rest of this post is about how recent research has explored fixing the inference side without giving up that simplicity.
Consistency models
Consistency models [2] were the first serious attempt at fixing the inference problem. Rather than learn the velocity and integrate it, learn a function that maps any point on the trajectory directly to the clean endpoint $x_0$:
Apply this once from pure noise, and you get a clean image. The model should give the same clean answer from any point on the same trajectory. Same idea as the equation above, drawn along one trajectory:
same trajectory: noise side clean side z_T ─────── z_t ─────── z_s ─────── x_0 f_θ(z_T, T) → x_0 f_θ(z_t, t) → x_0 f_θ(z_s, s) → x_0 f_θ(x_0, 0) → x_0
For this to work, the function needs two properties. First, the boundary condition: at $t = 0$ (or more precisely, a small cutoff $\varepsilon$ near zero), the function must be the identity, $f_\theta(x_0, \varepsilon) = x_0$. A completely clean image maps to itself. Without it, the network could satisfy the rest of the loss by outputting a constant; the boundary condition pins one end of the function to something meaningful.
Second, the consistency condition: any two points on the same PF-ODE trajectory must map to the same $x_0$. If two different noisy versions of the same clean image both pass through the network, they should produce identical outputs. Without this, the network is only locally trained at individual points and the function never becomes globally coherent. The figure below shows what this looks like: every point along one trajectory is required to map to the same destination.
How do you actually build $f_\theta$ so the boundary identity $f_\theta(x_0, \varepsilon) = x_0$ holds? The naive way is piecewise: define $f_\theta(x, t) = x$ when $t = \varepsilon$ and $f_\theta(x, t) = F_\theta(x, t)$ otherwise, where $F_\theta$ is a free neural network. This works for the discrete-time loss but breaks the moment you want continuous-time training, because the function is not differentiable at $\varepsilon$ and the continuous-time loss requires a clean derivative through $f_\theta$.
The fix the paper uses, and the one that has stuck since, is to wire the boundary identity into the architecture algebraically with a skip / output split:
At $t = \varepsilon$ the formula collapses to $f_\theta(x, \varepsilon) = 1 \cdot x + 0 \cdot F_\theta = x$. The boundary condition is true by construction; the loss never has to enforce it. Because $c_\text{skip}$, $c_\text{out}$, and $F_\theta$ are all differentiable in $t$, so is $f_\theta$. That matters for continuous-time consistency training, which needs a clean derivative of $f_\theta$ with respect to $t$.
The specific functional forms for $c_\text{skip}$ and $c_\text{out}$ are inherited directly from the EDM (elucidating diffusion models) preconditioning [10].3
The skip weight $c_{\mathrm{skip}}(t)$ rises toward one as $t \to \varepsilon$ while the trunk weight $c_{\mathrm{out}}(t)$ falls to zero, so the wired output $f_\theta(z_t, t) = c_{\mathrm{skip}}(t)\, z_t + c_{\mathrm{out}}(t)\, F_\theta(z_t, t)$ becomes nearly the identity on $z_t$ near the clean end. The boundary condition falls out of the wiring; the loss does not have to learn it.
Enforcing consistency via self-distillation
Here is the problem: you never directly observe which trajectory any $z_t$ belongs to. You cannot enumerate all the $(z_t, z_s)$ pairs that should agree. What you can do is take two adjacent points on the same trajectory, $z_t$ and $z_{t-\Delta}$ separated by a small step, and ask that their predictions agree:
The EMA copy $\theta^-$ is updated slowly after each training step, typically $m \approx 0.99$, so the target moves at roughly 1% of the speed of the main network. This keeps the target stable enough to learn against. Without it, both sides of the loss update simultaneously and they can easily converge to the same wrong answer: outputting a constant everywhere, which technically satisfies the loss but is completely useless for generation.
The stop-gradient on the target side breaks this symmetry. Gradients only flow through the left side of the loss, so only $\theta$ is updated to chase the target. The target then drifts slowly via the EMA rule. This is the same target network trick that stabilised DQN in deep RL: when the network is regressing toward a target derived from itself, you keep the target frozen (or slowly-moving) so the optimisation has something fixed enough to converge to.
To get the adjacent point $z_{t-\Delta}$ on the same trajectory as $z_t$, you need to take one step of the PF-ODE. This is where the teacher and student framing becomes explicit. In consistency distillation (CD), a pretrained diffusion model acts as the teacher: it provides reliable one-step ODE moves that land on the true trajectory, and the student learns to jump directly to $x_0$ from any point on those teacher-generated trajectories. In consistency training (CT), there is no external teacher; the network has to produce its own one-step ODE moves to generate training pairs, which introduces additional noise and makes training harder to stabilise. CD is faster to converge and produces better results; CT avoids the dependency on a pretrained teacher at the cost of more careful engineering.
Worth pinning down the language here, because three different things in this post all get called “teacher” at various points and they are not the same. Data supervision means clean targets read directly from training pairs, like flow matching’s $v = x_0 - x_1$. A pretrained teacher is an external network trained separately, used in CD and later in Align Your Flow (AYF); quality is capped at whatever the teacher can do. The EMA copy $\theta^-$ is the network’s own slowly-moving lag of itself, used in CT, CTM, Shortcut, and the consistency half of MeanFlow. CT and CD differ exactly in this: CT has only the EMA copy, CD has both. From here on I will say “EMA copy” when I mean the internal lag and “pretrained teacher” when I mean a separately trained network.
The discretisation curriculum
There is a subtlety in how consistency models are trained. You divide the time axis into $N$ discrete steps. Adjacent training pairs are always one step apart, so the gap $\Delta = T/N$.
If $N$ is small, the gap is large. The two adjacent points are far apart on the PF-ODE trajectory. The training signal is strong (there is a lot of distance between the two predictions to align) but the targets are noisy. Taking a large step along the PF-ODE introduces large discretisation error, so $z_{t-\Delta}$ is only approximately on the right trajectory. You are training the network to agree with a somewhat wrong target.
If $N$ is large, the gap is small. The targets are very accurate (a tiny ODE step is nearly exact) but the training signal is weak. The two adjacent points are so close that their predictions are already similar. The loss gradient is tiny and training makes almost no progress.
Neither extreme works. The fix is a curriculum: start with small $N$ (coarse, strong signal, rough targets), then progressively increase $N$ (fine, weak signal, accurate targets). The network first learns a rough consistency function, then refines it. Slide $N$ in the demo below to see the tradeoff: at $N=1$ the Euler step from $z_t$ falls far off the true curve (large red gap, strong gradient); at $N=8$ it tracks the curve closely but the gradient barely moves the network.
N=1: one step covers the whole trajectory. The tangent step at z_t lands far from the true curve. Large training signal, noisy target.
Discrete-time vs continuous-time
What I described above is the discrete-time formulation: pick a grid of $N$ noise levels, define adjacent pairs on that grid, and run the curriculum on $N$. The grid is a crutch. It exists because we cannot directly enforce the consistency condition over a continuum, only at sampled pairs of points. The whole curriculum on $N$ is just managing the bias-variance tradeoff that the grid introduces.
The continuous-time formulation removes the grid entirely. Differentiating the consistency condition $f(z_t, t) = f(z_{t-\Delta}, t-\Delta)$ as $\Delta \to 0$ gives a PDE-style identity: $\partial_t f + v(z_t, t) \cdot \partial_z f = 0$ along the PF-ODE.4 The training loss enforces this identity at sampled $(z_t, t)$ pairs, no adjacent point needed, no grid to schedule. sCT and sCD (the simplified continuous-time variants of CT and CD) [9] use this formulation and produce sharper results than the discrete-time version, because the bias from finite $\Delta$ is gone. The cost is a Jacobian-vector product (JVP) through the network to compute $\partial_z f \cdot v$. A JVP is the Jacobian times a vector, but you never have to materialise the full Jacobian: forward-mode autodiff computes it in a single modified forward pass at roughly the same cost as a normal one.5 MeanFlow uses the same JVP machinery later for a different purpose.
Consistency models were the first method to show you can generate decent images in one step, which was not obvious before 2023. iCT (improved consistency training) [3] improved substantially over the original with a bundle of training stability tricks: pseudo-Huber losses, a lognormal noise schedule, and progressive discretisation step doubling.6 Even those required considerable engineering effort just to be reliable.
The training target is always behavioural: it constrains what the network outputs at adjacent pairs of points, not what the underlying field should be. There is no ground truth for $f(z_t, t)$ that exists independently of the network. The optimal function is defined only implicitly, via the consistency condition and boundary condition, and can only be learned by having the network agree with itself across adjacent pairs. This is inherently noisy and sensitive to hyperparameters.
The deeper limitation: consistency models are stuck. They can only jump to one destination, the endpoint $x_0$. The function signature is $f(z_t, t) = x_0$; you tell it where you are and what time it is, and it predicts the endpoint. You cannot ask it to jump to an intermediate point. Multi-step generation therefore requires running the network multiple times and renoising between each evaluation, a clunky workaround that does not actually use the trajectory structure. But what if the jump function could land anywhere, not just $x_0$?
Consistency trajectory models: any-to-any jumps
CTM [4] generalises consistency models. Where consistency models always jump to the end of the PF-ODE trajectory, CTM lets the function jump to any point along it. This is the two-time function:
With this object you can take large or small steps, land at any intermediate point on the trajectory, and compose multiple jumps to refine a generation. For this to be well-posed, the function has to satisfy the semigroup property. If you jump from $t$ to some intermediate $u$, and then jump from $u$ to $s$, you should get the same result as jumping directly from $t$ to $s$:
Drag the split point $u$ in the figure below to see this in action: the direct jump (top arc) and the two-leg composition (bottom arcs) always end at the same destination, no matter where you split.
Drag the split point. Both routes (direct and two-step) always land at the same destination.
Training enforces this by sampling triples $(r, s, t)$ with $r < s < t$ and comparing the direct jump $G(x_t, t, r)$ against the composed two-step jump:
The flexible jump function makes multi-step generation more natural than consistency models: you chain calls with progressively smaller target times, no renoising needed. At the time of publication, CTM held the best single-step FID numbers (see the results table below).
The limitation it inherits from consistency models: the training target is still self-referential. $G_{\theta^-}$ is the network evaluated at a slightly lagged version of itself. There is no ground-truth two-time map that exists independently of the network; the only supervision comes from the model agreeing with itself across different decompositions. This makes training more stable than consistency models (because the semigroup structure is richer), but the fundamental self-referential nature remains. CTM is also fiddly in practice: random triples $(r, s, t)$, two separate network evaluations on the target side, careful coordination of all the moving parts.
Shortcut models
Where CTM works with continuous-time triples $(r, s, t)$ and pays for that flexibility with fiddly training, shortcut models [5] commit to a discrete set of jump sizes and make the training procedure radically simpler. The idea: condition the network on both the current noise level $t$ and the desired step size $d$. The network learns to predict where you will end up after a jump of size $d$ from $z_t$. The step size is an input, not a fixed constant.
A regular flow matching network only knows “I am at noise level $t$.” A shortcut model knows “I am at noise level $t$, and I want to travel a distance of $d$ in one step.” With that extra information, it can calibrate its prediction to the correct jump size, and you can ask it to take different step sizes at different points during generation.
The bootstrapping training procedure
How do you train this? You cannot compute the ground-truth $z_{t-d}$ directly, because it would require running the full ODE. The trick is to build the target out of smaller steps the network can already make. Two half-steps from the (stop-gradient) EMA copy of the network are composed into a single full-step target the student is trained to match. The picture first, equations after.
In equations, this is the semigroup property enforced discretely:
In practice, training starts with the smallest steps (where the half-step approximation is most accurate) and progressively learns larger steps using the smaller ones as building blocks. The network learns one-step jumps first, then two-step, then four-step, bootstrapping upward. At inference, you choose any step count: one for speed, many for quality.
Frans et al. draw the same construction with the actual loss notation overlaid; reproduced for cross-reference.

Shortcut models enforce composition by directly comparing network outputs: no differentiation through the network, no JVP, just a fast per-step training update. The tradeoff is that the discrete half-step approximation introduces small errors that compound when you compose many steps; and like CTM and consistency models before it, the training target is still self-referential. The next two methods both push against that self-reference. Align Your Flow does it by importing ground truth from outside (a pretrained teacher); MeanFlow does it from the inside (an exact identity that lets the network supervise itself against quantities readable directly from data).
Align Your Flow: distilling the jump function
Both CTM and Shortcut models work with the same flow-map object: a two-time network $f_\theta(x_t, t, s) = x_s$ that jumps from any noise level to any cleaner level in one forward pass. They train it from scratch with self-referential targets and pay for that with curriculum schedules and EMA copies of themselves on the target side. Align Your Flow [8] takes a different bet: instead of training the flow map from scratch, distill it from a pretrained diffusion teacher whose ODE trajectories are the ground truth.

This framing resolves something that was implicit in CTM but never fully confronted. CTM trains the jump function so that composed shorter jumps reproduce longer ones, but it never asks whether the jump function is actually correct, only whether it is internally consistent. A pretrained teacher changes that: the teacher’s ODE trajectories are ground truth, and the student’s jumps are trained to trace them. Internal consistency is still enforced, but now there is an external anchor.
The paper also proves that consistency models eventually get worse with more steps. Theorem 3.1: for an isotropic Gaussian data distribution, there exist consistency models arbitrarily close to optimal in $L_2$ such that increasing the sampling step count beyond some $N$ increases the Wasserstein-2 distance to the true distribution.7 The empirical version (Fig. 5 of the paper, on isotropic Gaussian data with standard deviation $c = 0.5$) is just as stark: multi-step CM sampling peaks around 2 steps and then degrades. The mechanism is renoising. CMs jump to clean between steps and reinject Gaussian noise to get back onto the trajectory; over many steps that injected noise does not align with the teacher’s PF-ODE trajectory and errors compound.
Flow maps avoid this by construction: they map directly between any two noise levels in one step, never leaving the trajectory. The paper does not formally prove they monotonically improve, but empirically they keep getting better with more steps, exactly where CMs fall apart.
Distilling the jump function from a teacher raises a practical question: how do you enforce the consistency constraint? AYF gives two answers, borrowing the fluid-dynamics distinction between Eulerian (fixed observer, watch the field) and Lagrangian (move with the particle) frames. The two losses differ in which time variable they perturb.
| Objective | What's varied | Why it works | Empirical role |
|---|---|---|---|
| EMD (Eulerian Map Distillation) | Endpoint $s$ fixed, perturb starting time $t$; check that $f_\theta(x_t, t, s)$ is invariant as $t$ moves along the teacher trajectory. | This loss generalises both the continuous-time consistency loss (when $s = 0$) and the flow matching loss (as $s \to t$); structurally the right object to optimise. | Primary loss in all main results. |
| LMD (Lagrangian Map Distillation) | Starting point $t$ fixed, perturb endpoint $s$; check that $f_\theta(x_t, t, s)$ moves correctly as $s$ slides along the trajectory it predicts. | Uses the teacher's instantaneous velocity at the predicted point, so it stays faithful to the flow geometry the teacher defines. | Used as a stabiliser; on its own produces over-smoothed samples on real images, per the paper's ablations. |
To replace classifier-free guidance during distillation, AYF uses autoguidance: the teacher is mixed with a weaker checkpoint of itself, $v_\phi^{\text{guided}} = \lambda v_\phi + (1 - \lambda) v_\phi^{\text{weak}}$ with $\lambda$ sampled uniformly from $[1, 3]$. This steers samples away from low-quality regions without the overshooting failure mode CFG can have.
Empirically, a small AYF student beats much larger distillation baselines at fewer network function evaluations (NFEs). The efficiency comes from the teacher anchor: unlike CTM, the student does not waste capacity reconciling self-generated targets at high noise levels where those targets are most unreliable. Full numbers are in the table at the end of the post.
MeanFlow: ground truth for the jump function
MeanFlow [6] finds a quantity the network can predict whose true value is computable directly from data, no teacher required. That quantity is the average velocity.
Average velocity: a ground-truth two-time quantity
So what does “average velocity” actually mean here? It is the same thing it meant in physics class: total displacement divided by elapsed time. If you go from $z_t$ to $z_r$ over an interval of length $t - r$, the average velocity is just one divided by the other:
This looks unhelpful at first because $z_r$ is exactly the thing we cannot compute without integrating the ODE. But here is where flow matching does us a favor. Because the conditional paths are linear interpolations $z_t = (1-t)x_0 + tx_1$, the numerator $z_t - z_r$ collapses cleanly. Subtract the two interpolations:
Divide by $(t-r)$ and the time variables cancel completely:
That is the punchline. The average velocity is a fixed quantity for each training pair $(x_0, x_1)$, readable directly from data; no network evaluation, no self-reference, no approximation. And one-step generation falls out for free: start at pure noise, subtract the average velocity over the full interval, you have $x_0$.
The catch: this beautiful identity is only directly usable for the full interval $[0, 1]$ where you have ground-truth $(x_0, x_1)$ pairs. For arbitrary intermediate triples $(z_t, r, t)$ during training, computing $\bar{u}$ directly would require running the ODE, which is the slow integration we are trying to avoid. The next subsection is how MeanFlow gets around that.
The MeanFlow identity
Computing $z_r$ requires running the PF-ODE from $z_t$ to time $r$, the slow integration we just said we want to avoid. MeanFlow derives an equivalent form that does not require $z_r$ at all. Start from the definition rewritten as an integral:
Now differentiate both sides with respect to $t$. The right side uses the fundamental theorem of calculus; the left side uses the product rule:
This identity gives a target for $\bar{u}$ with no integrals and no ODE simulation. The two pieces on the right side play very different roles. The first, $v(z_t, t)$, is data-supervised, the same target flow matching uses. The second, $d\bar{u}/dt$, is the network differentiating its own output. So the MeanFlow target is a mix of data supervision and self-reference; the identity is exact, but the self-referential half still has to be stabilised. That tension is what the next subsection is about.
Computing $d\bar{u}/dt$: the Jacobian-vector product
The term $d\bar{u}/dt$ is a total derivative: it measures how the network output changes as $t$ increases, accounting for two effects simultaneously, the explicit dependence on $t$ as a conditioning input and the implicit dependence through $z_t$ (which moves along the flow as $t$ changes). Expanding via the chain rule:
The first term is a Jacobian-vector product (JVP): the Jacobian of the network output with respect to its input $z$, dotted with the velocity vector $v(z_t, t)$. This is computed via forward-mode automatic differentiation, a single modified forward pass through the network. In PyTorch: torch.func.jvp. In JAX: jax.jvp. The overhead in practice is a fraction of an extra forward pass, much less than running a full second forward pass for a teacher network.
The full training loss applies stop-gradient to the entire target to avoid second-order gradients:
Why this loss is hard to train
α-Flow [7] takes apart the MeanFlow loss and shows that an exact identity does not guarantee a stable optimisation: the loss splits into two components that fight each other in the early stages of training. The decomposition is called TFM/TC.
When $r = t$, the interval collapses to a single point and the average velocity over a zero-length interval equals the instantaneous velocity. The MeanFlow identity reduces to $\bar{u} = v$, and the loss becomes exactly the standard flow matching loss. MeanFlow uses $r = t$ for a large fraction of training samples (around three-quarters in the paper’s main configuration). Why spend that much of training on the degenerate case that ignores the average velocity entirely?
The decomposition is:
TFM is the flow matching component. It pushes the network to predict the instantaneous velocity field, supervised directly by data and stable to optimise. The large-fraction $r=t$ sampling ensures TFM dominates early training.
TC is the consistency enforcement component. It uses the JVP to ensure predictions compose correctly across intervals. This is the part that gives MeanFlow its structure beyond plain flow matching, but it depends on a JVP through the network, which is noisy at high noise levels.
Why? The TC gradient uses the JVP: the Jacobian of the network output with respect to input $z_t$, multiplied by the velocity vector. At high $t$ (near pure noise) the input carries almost no semantic signal. The network’s weights at this early stage are unstructured, so the Jacobian of an unstructured network with respect to its input is essentially random: large in magnitude, arbitrary in direction. Multiplying this random matrix by the velocity vector produces a JVP that points nowhere useful.
The consequence is that TC gradients at high $t$ are large, random vectors that actively conflict with TFM gradients. α-Flow documents this conflict and uses it to motivate a curriculum: a parameter $\lambda \in [0,1]$ interpolates between pure TFM ($\lambda=0$, just flow matching, completely stable) and full MeanFlow ($\lambda=1$). Training starts at $\lambda=0$ and increases as the velocity field converges, by which time the Jacobian at high $t$ begins to encode which direction the trajectory is heading, and the JVP carries real signal.
Same coarse-to-fine principle as the discretisation curriculum in consistency models, applied to a continuous parameter: stabilise the data-supervised component first; turn on the self-referential one only after the velocity field has converged enough for the JVP to mean something.
Where this leaves us
Stepping back, the methods sit on a continuum from cheap-and-local training signals to expensive-and-global ones.
| Method | Composition | Training target | Inference | Per-step cost |
|---|---|---|---|---|
| Flow matching | none | data-supervised | multi-step | regression |
| Consistency models | jump to $x_0$ | self-referential (EMA) | one-step | regression |
| CTM / Shortcut | any-pair / discrete sizes | self-referential (EMA) | one- or few-step | regression |
| Align Your Flow | any-pair via distillation | teacher-anchored | one- or few-step | regression + teacher |
| MeanFlow | continuous (semigroup identity) | data-supervised + self-referential mix | one-step | regression + JVP |
MeanFlow is the only row with a ground-truth target and one-step inference; it pays with the JVP and the training conflict from the previous section.
There is a structural reason this looks like a continuum and not a set of unrelated tricks. The signal you can compute cheaply is local: an instantaneous velocity from data, or a short ODE step from a teacher. The thing you want is global: a one-step jump that has to be correct over a long interval. Self-reference, the network agreeing with a lagged copy of itself, is the only way to bridge the two. It is also unstable until the data-supervised part is solid, which is why every method here needs a curriculum that turns the self-referential part on gradually. A pretrained teacher is an external oracle for the long-jump answer; an EMA copy is an internal one. Which you pick mostly depends on whether you have a good teacher available.
Two years ago none of these numbers existed. The gap with multi-step diffusion is closing faster than most expected. CIFAR-10 at 1 NFE looks effectively saturated in this family; the ImageNet rows show what teacher anchoring buys you, with AYF at 2 NFE reaching the best FID in the table and a 280M-parameter AYF-S beating the 1.5B-parameter sCD-XXL on IN-512.
| Method | NFE | Benchmark | FID ↓ | Training |
|---|---|---|---|---|
| Consistency Models [2] | 1 | CIFAR-10 | 3.55 | distillation / from scratch |
| iCT [3] | 1 | CIFAR-10 / IN-64 | 2.51 / 3.25 | from scratch |
| CTM [4] | 1 | CIFAR-10 / IN-64 | 1.73 / 1.92 | distillation + adversarial |
| MeanFlow [6] | 1 | IN-256 | 3.43 | from scratch |
| α-Flow [7] | 1 / 2 | IN-256 | 2.58 / 2.15 | from scratch (DiT) |
| Align Your Flow [8] | 1 | IN-64 | 2.98 | distillation (EMD) + optional adversarial |
| 2 | IN-64 | 1.25 | ||
| 4 | IN-512 (280M) | 1.70 0.24s |
IN = ImageNet. NFE = network function evaluations. AYF-S at 4 NFE (FID 1.70, 0.24s) outperforms sCD-XXL at 2 NFE (FID 1.88, 0.50s) using 5× fewer parameters.
This is one branch of the one-step literature. Parallel lines, flow rectification, distribution matching distillation, and adversarial distillation, currently dominate at SDXL-scale text-to-image and are not covered here.
A few things still feel unresolved to me. Guidance is the obvious one. CFG is what makes large-scale conditional diffusion deployable, and none of the one-step methods have a clean equivalent. AYF’s autoguidance is the best answer so far, but it needs a second trained model and only really works in the distillation setting. The architectures are also borrowed: every model here is a diffusion U-Net or DiT being repurposed, with the skip/output split from EDM and the two-time conditioning bolted on as an extra input embedding. I have not seen anyone ask what a network designed for the one-step objective from scratch would look like. MeanFlow’s $\bar u = x_1 - x_0$ identity is more fragile than it looks too; it relies on linear interpolation paths, and the moment you want curved schedules (which matter for sample quality at scale) the algebra stops and you are back to the integral form. And the benchmarks here are all ImageNet at 64, 256, and 512. A real one-step video model does not exist yet.
My guess is the next jump is either an architecture redesign that bakes in the boundary and composition constraints, or a clean way to do guidance at one step. The compositional principle feels right. What is missing is the engineering around it.
What I find most satisfying about this whole family is that the composition rule is the single unifying principle, even though it can look like a different trick in each paper. Every method is a different answer to the same question: how do you enforce that a long jump equals composed shorter jumps, while keeping training tractable? Consistency models do it globally via self-distillation. CTM generalises to any pair of times. Shortcut models go discrete and condition on step size. Align Your Flow imports an external teacher and shows the ideas transfer cleanly to distillation at scale. MeanFlow goes continuous via an exact calculus identity, with no teacher at all. Once you see that, the curricula, the EMA copies, the JVP, and the 75% border-case sampling stop looking like separate tricks.
References
- Lipman et al., Flow Matching for Generative Modeling, 2022.
- Song et al., Consistency Models, 2023.
- Song & Dhariwal, Improved Consistency Training for Consistency Models, 2023.
- Kim et al., Consistency Trajectory Models: Learning Probability Flow ODE Trajectory of Diffusion, ICLR 2024.
- Frans et al., One Step Diffusion via Shortcut Models, ICLR 2025.
- Geng et al., MeanFlow: Unified Average-Velocity Learning for Flow-Based Generative Models, 2025.
- Zhang et al., α-Flow: Unifying Flow Matching and Consistency Models, 2025.
- Sabour et al., Align Your Flow: Scaling Continuous-Time Flow Map Distillation, 2025.
- Lu & Song, Simplifying, Stabilizing & Scaling Continuous-Time Consistency Models, 2024.
- Karras et al., Elucidating the Design Space of Diffusion-Based Generative Models, NeurIPS 2022.
- Song et al., Score-Based Generative Modeling through Stochastic Differential Equations, ICLR 2021.
-
This marginal-equivalence is the result that opened up the entire deterministic-sampler line of work in diffusion (DDIM-style integrators, exact likelihood evaluation, every method in this post). The claim: the PF-ODE shares the same time-marginal distributions $p_t(x)$ as the stochastic diffusion process for every $t$, even though one is deterministic and the other is not. The PF-ODE drift is $\frac{dx}{dt} = f(x,t) - \tfrac{1}{2}g(t)^2 \nabla_x \log p_t(x)$, with $f$ and $g$ the SDE’s drift and diffusion coefficients. The proof is direct: both processes induce the same Fokker–Planck equation for $p_t(x)$, so any solution to one is a solution to the other at the marginal level (Song et al. 2021, Appendix D.1). Trajectories differ, marginals do not. ↩
-
Any source distribution works in the flow-matching framework; Gaussian is convenient because the velocity calculation collapses cleanly, not because it is required. Recent work on optimal-transport flow matching exploits this freedom directly. ↩
-
This is a deliberate inheritance choice, not a derivation. EDM uses these schedules to keep the network’s input and output magnitudes well-conditioned across noise levels (specifically $c_\text{skip}(t) = \sigma_\text{data}^2 / (\sigma_\text{data}^2 + t^2)$ and $c_\text{out}(t) = t \cdot \sigma_\text{data} / \sqrt{\sigma_\text{data}^2 + t^2}$ in the EDM noise parameterisation). Borrowing them lets consistency models drop into existing diffusion architectures with no structural changes, just a different head and loss. ↩
-
Where the PDE comes from: differentiate $f(z_t, t) = f(z_{t-\Delta}, t-\Delta)$ with respect to $\Delta$ at $\Delta = 0$. The right side gives $-\partial_t f - \partial_z f \cdot (dz/dt)$. Along the PF-ODE, $dz/dt$ is the velocity $v(z_t, t)$. Setting the derivative to zero (so consistency holds for every small $\Delta$, not just at sampled pairs) gives $\partial_t f + v(z_t, t) \cdot \partial_z f = 0$. This is the transport equation for $f$ along the flow, the method-of-characteristics statement that $f$ is constant along PF-ODE trajectories. ↩
-
The JAX autodiff cookbook is a good primer on JVPs and forward-mode autodiff if you want a refresher. ↩
-
Briefly: pseudo-Huber is a smooth approximation to the Huber loss, which behaves like $L_2$ near zero and like $L_1$ further out; it cuts the variance contribution from a few large errors that otherwise destabilise consistency training. The lognormal noise schedule concentrates training samples around noise levels where the loss is most informative, instead of uniformly over $t$. Progressive step doubling runs the discretisation curriculum on a $\log_2 N$ schedule, doubling $N$ at preset training milestones rather than tuning a continuous ramp. iCT also drops the EMA target network used in the original CT, which is a more important change than its placement in the trick list suggests. ↩
-
To be precise about the existential form: the theorem says that for any $\delta > 0$, there exists a consistency model $f$ with $\mathbb{E}\lVert f(x_t,t) - f^{\ast}(x_t,t)\rVert_2^2 < \delta$ uniformly in $t$, and some $N$ beyond which extra sampling steps make the generated distribution worse in $W_2$. It is therefore not a statement about every imperfect CM, but about the existence of arbitrarily-close-to-optimal ones with this pathology, which is enough to make the theorem load-bearing in the post’s argument: the failure mode is not a “you trained badly” artifact. The proof and the Gaussian assumption together yield a closed-form analysis; whether the result extends to non-Gaussian data is not formally settled. ↩