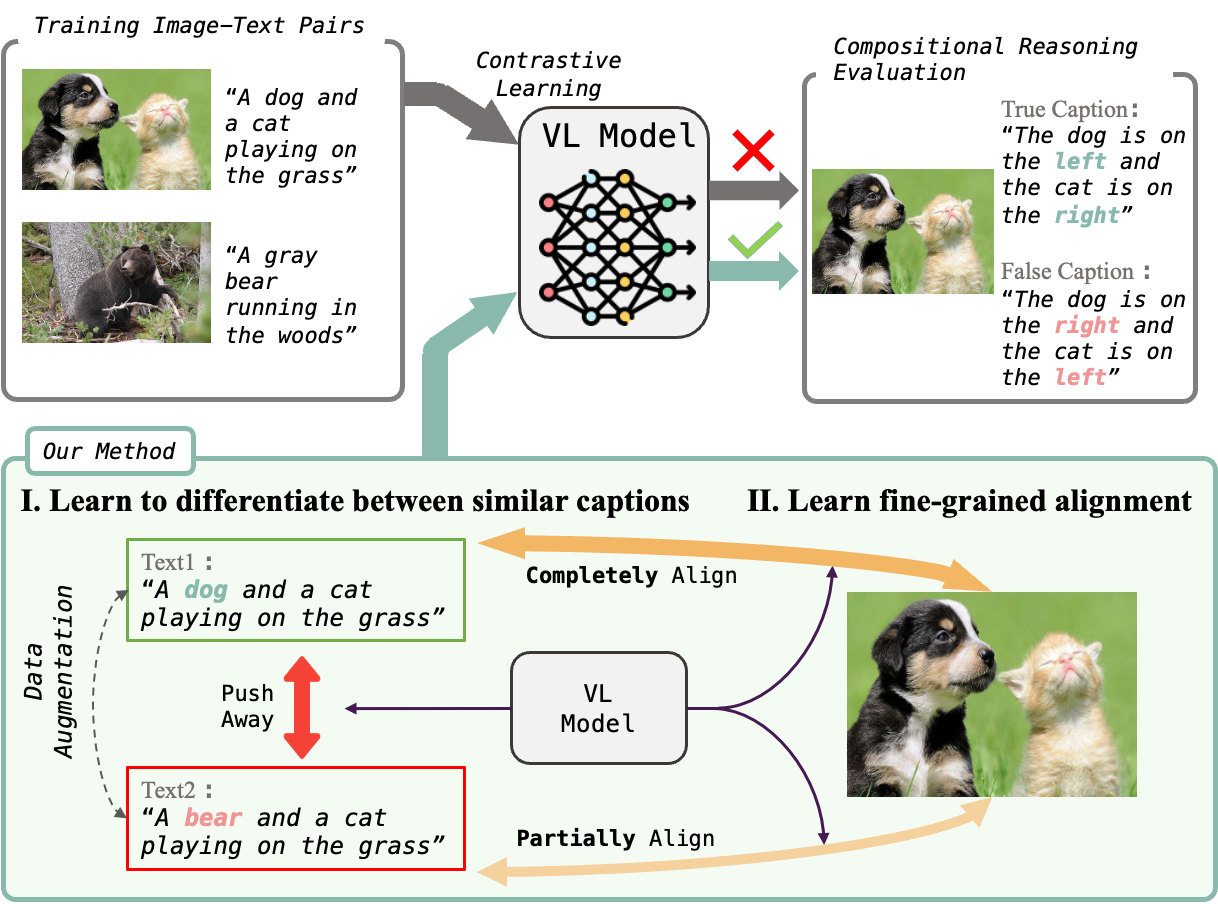




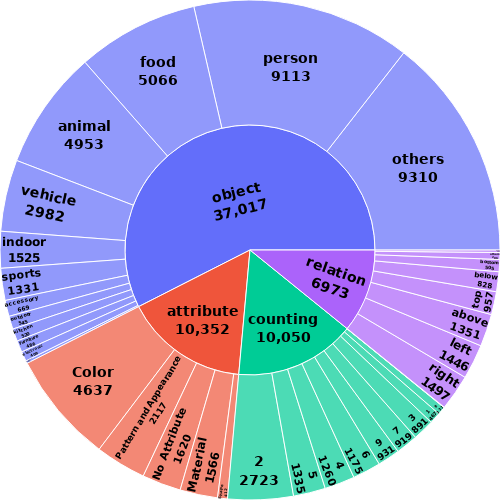

Setup. We evaluated a range of state-of-the-art Visual Language Models (VLMs) and Multimodal
Large Language Models (MLLMs) including well-known foundational models like CLIP, SigLip, and emerging MLLMs
like Idefics2 and GPT-4V. These evaluations covered image-text matching tasks, where models chose the correct
image from two captions or the correct caption from two images, and adapted visual question answering formats
for MLLMs, assessing alignment with captions across paired images.
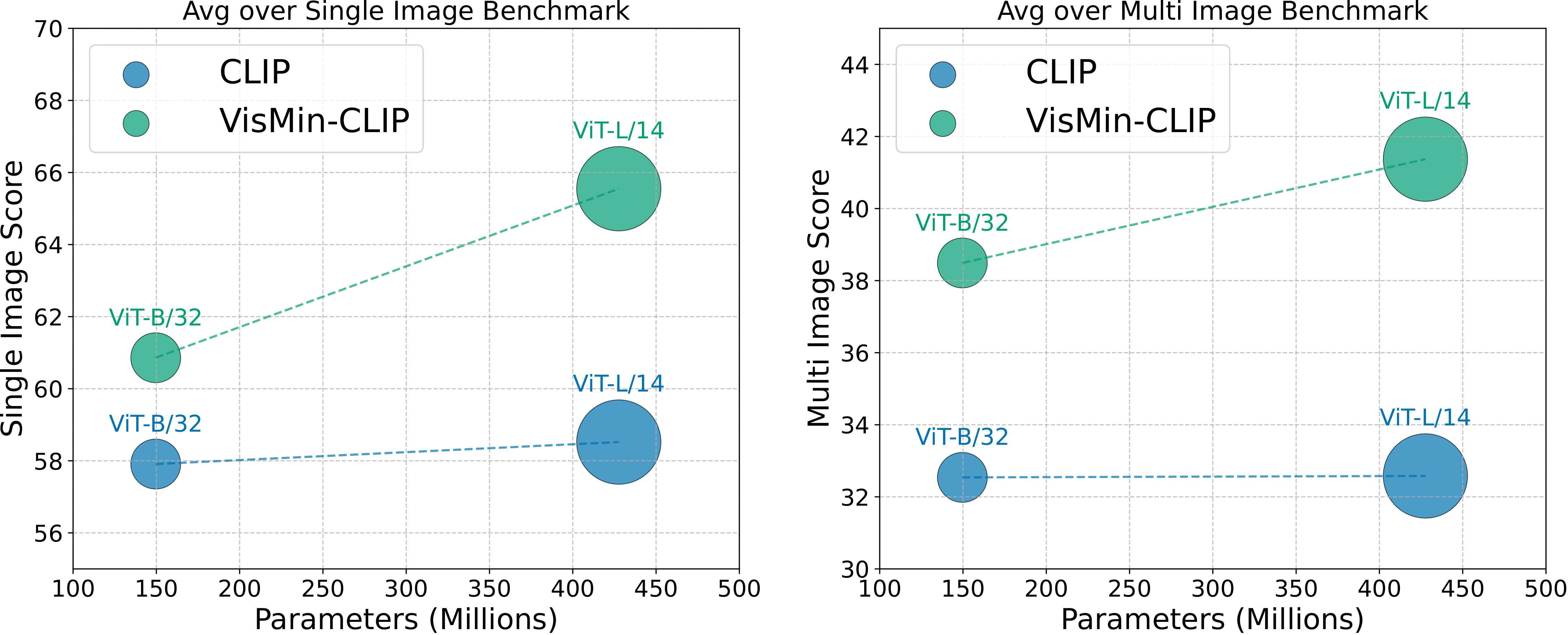
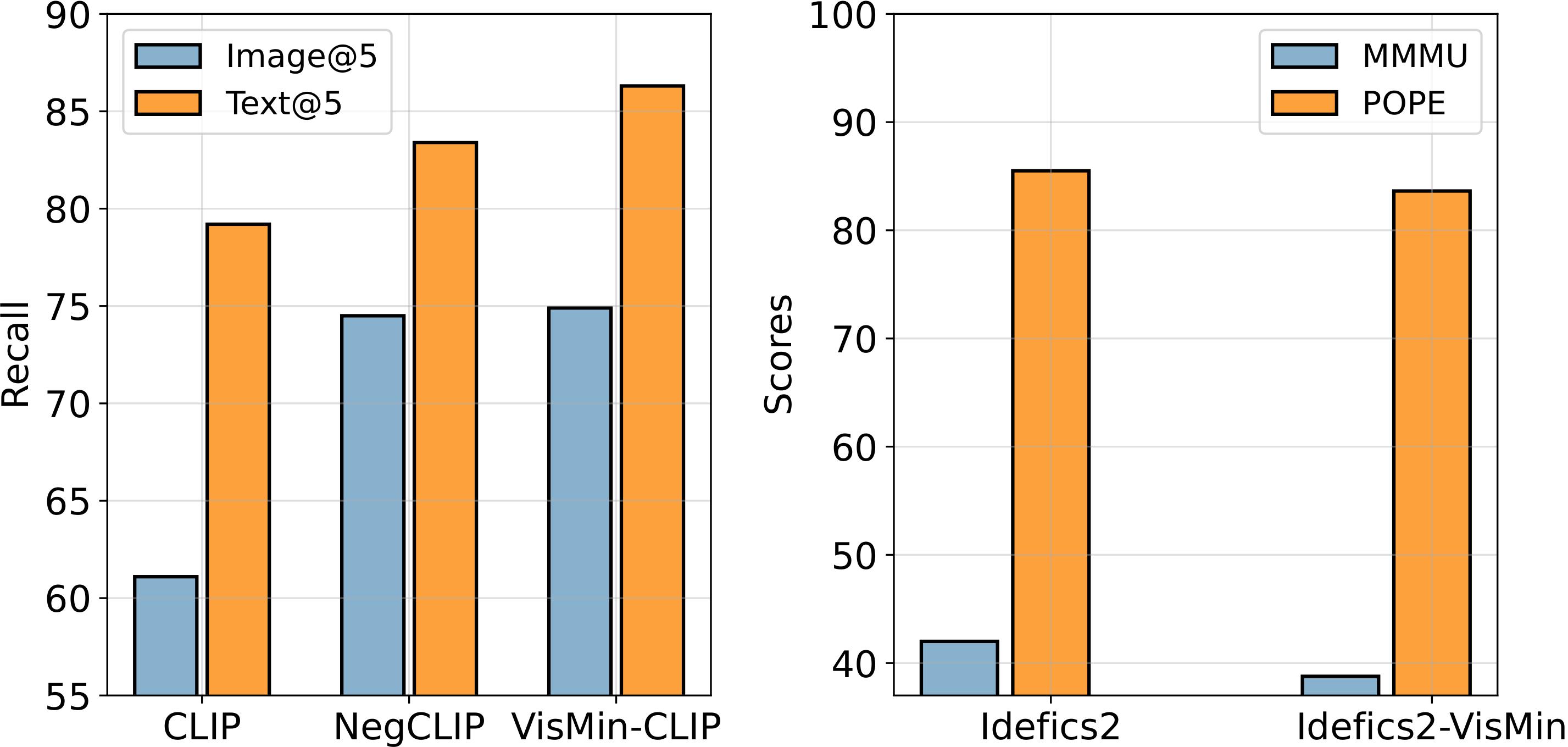
How do state-of-the-art VLMs perform on VisMin? Both CLIP-family and Multimodal LMs (MLLMs) excel in object and attribute understanding but struggle with spatial relationships and counting. Larger CLIP models don't improve spatial understanding. Open-source MLLMs struggle more with image-score (distinguishing similar images given a caption) than text-score (distinguishing similar captions given an image). GPT4-o is slightly better in spatial tasks than others, including Gemini 1.0 Pro, but still limited.